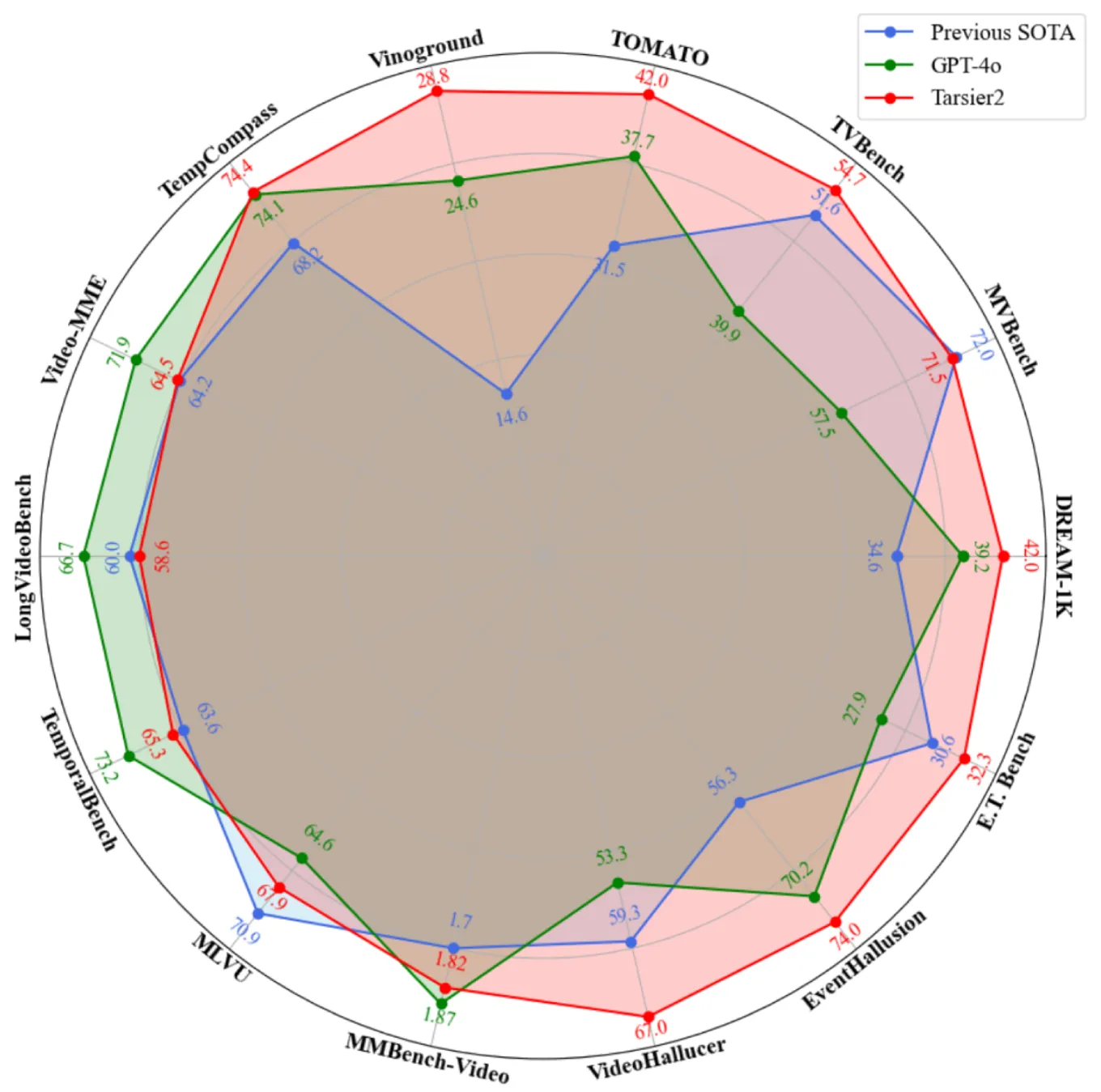
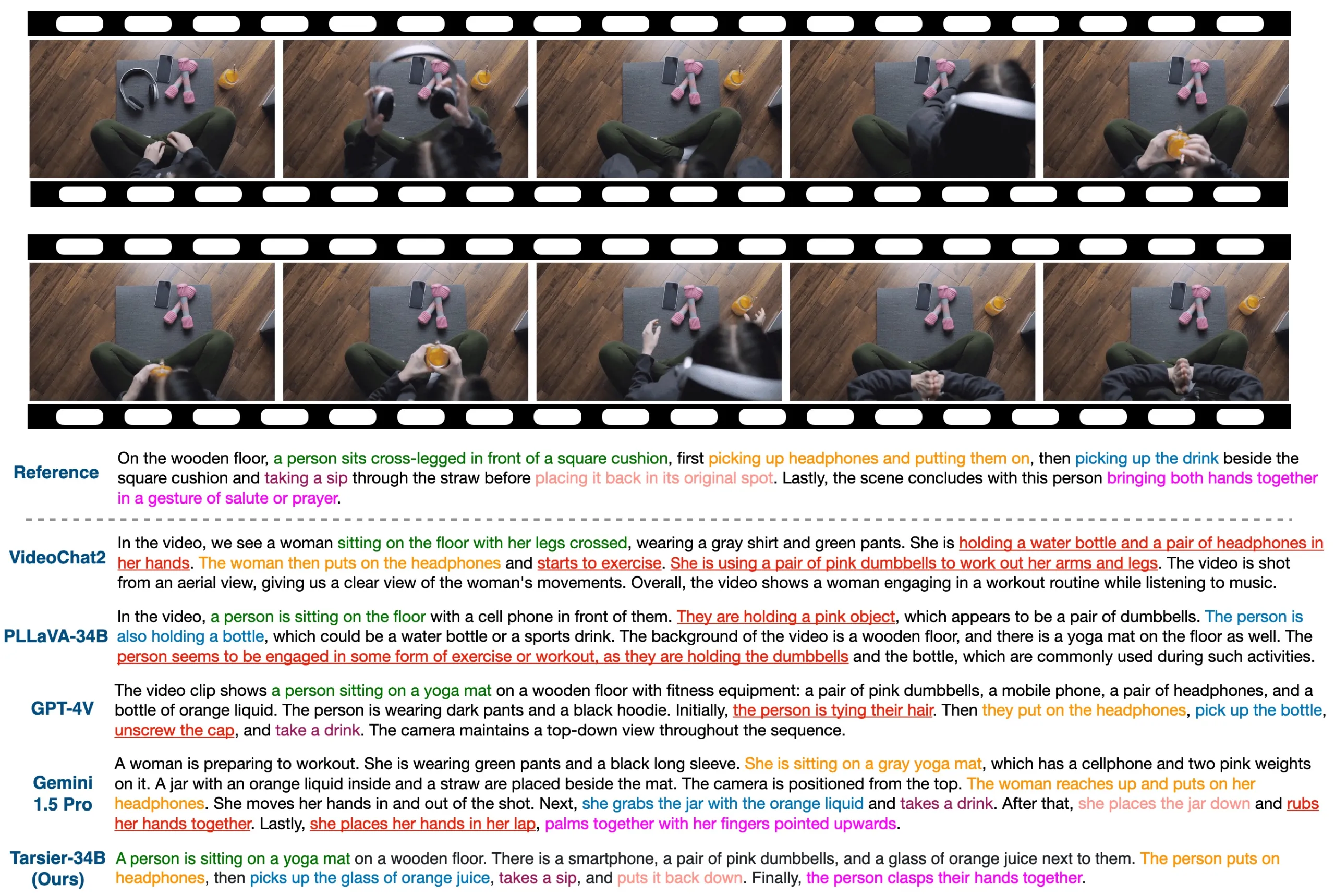
Tarsier2 Tarsier2是字节跳动研发的大规模视觉语言模型,擅长生成高精度视频描述并在多项视频理解任务中表现优异。其核心技术包括大规模数据预训练、细粒度时间对齐微调以及直接偏好优化(DPO)。该模型在视频问答、定位、幻觉检测及具身问答等任务中均取得领先成绩,支持多语言处理,具有广泛的应用潜力。 AI项目与工具 2025年06月12日 59 点赞 0 评论 540 浏览
Tarsier 字节跳动推出的一系列大规模视觉语言模型(LVLM),专注于视频理解任务,包括视频描述、问答、视频定位、幻觉测试等功能。 Ai开源项目 2025年06月05日 90 点赞 0 评论 631 浏览